Since 2017, Dora Matzke and I have been teaching the master course “Bayesian Inference for Psychological Science”. Over the years, the syllabus for this course matured into a book (and an accompanying book of answers) titled “Bayesian inference from the ground up: The theory of common sense”. The current plan is to finish the book in the next few months, and share the pdf publicly online. For now, you can click here or on the cover page below to read the first 565 pages [85 MB!]. Today we are adding nine chapters:
- The First Simplicity Postulate: Prior Probability
- Prior Probability As Expected Relative Predictive Performance [with František Bartoš, Riet van Bork, and Jan-Willem Romeijn]
- Interlude: The Primacy of Poincaré
- The Second Simplicity Postulate: Evidence and Predictive Performance [with Frederik Aust]
- The Strength of Evidence [with Frederik Aust]
- Surprise Lost is Confidence Gained [with Quentin F. Gronau]
- Diaconis’s Wobbly Coin
- The Coherence of Evidence Accumulation
- Senn’s Stubborn Mule [with Frederik Aust and Quentin F. Gronau]
Below is a description of the goals that precede each chapter, plus a chapter figure:
Chapter 19. The First Simplicity Postulate: Prior Probability
The previous chapter showed that scientists have a strong preference for simple models. This accords with Jeffreys’s razor which states that “variation is to be taken as random until there is positive evidence to the contrary”. The razor can be given a Bayesian implementation through two complementary simplicity postulates. In this chapter we focus on the first postulate, which holds that the preference for parsimony expresses itself through the unequal assignment of prior model probabilities, such that simple models are judged to be more plausible a priori than complex models. This entails that for an infinitely long series of increasingly complex models, the prior probabilities need to form a convergent series (Wrinch and Jeffreys 1921; 1923).

Chapter 20. Prior Probability As Expected Relative Predictive Performance [with František Bartoš, Riet van Bork, and Jan-Willem Romeijn]
This chapter is partly based on van Bork, Romeijn, & Wagenmakers (2024).
The first simplicity postulate has come under attack from all sides. In this chapter we revisit the critique of the philosopher Sir Karl Popper, who argued –in diametrical opposition to the first simplicity postulate– that a simple model can never be more probable than a complex, extended version. Popper assumed that the Bayesian prior model probability quantifies one’s intensity of conviction that a particular model is ‘true’, that is, the probability that the model contains an accurate reflection of the true data-generating process (i.e., reality). Here we generalize this definition to account for situations in which we know that all candidate models are false. In the new definition, prior model probability reflects relative predictive performance for expected data sets of infinite length.

Chapter 21. Interlude: The Primacy of Poincaré
This chapter summarizes the philosophy of science advocated by mathematician-physicist-philosopher Henri Poincaré. We show that Poincaré’s 1913 trilogy The Foundations of Science contains insights that form a central component of the later work by Wrinch and Jeffreys. Several of Poincaré’s key phrases and expressions resurface in the work of Jeffreys almost verbatim, further underscoring the similarities in philosophical outlook between Poincaré and Wrinch & Jeffreys.
Chapter 22. The Second Simplicity Postulate: Evidence and Predictive Performance [with Frederik Aust]
Scientific thinking generally respects the principle of parsimony known as Ockham’s razor: researchers favor simple models, to abandon them only when forced to do so by empirical data. Moreover, scientific claims are accepted only when they are supported by evidence – a claim without evidence is merely a conjecture or speculation.
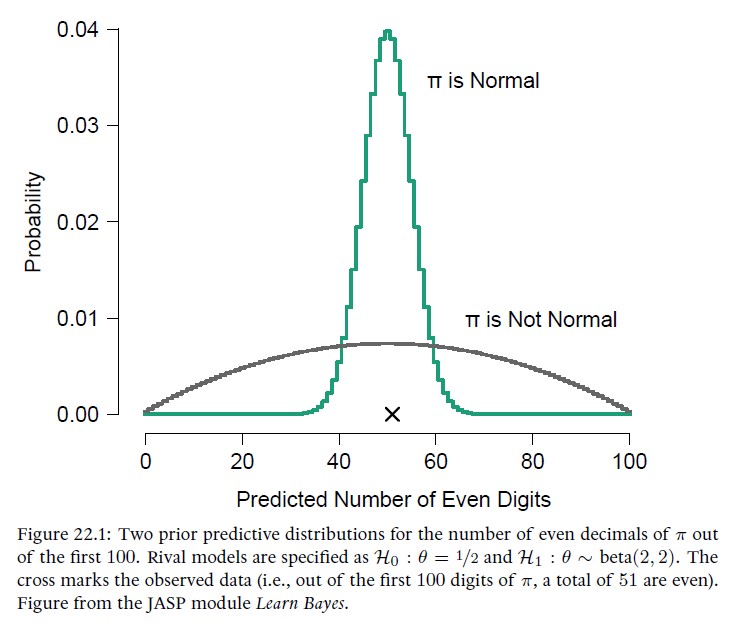
The Bayesian implementation of Ockham’s razor consists of two blades or simplicity postulates. The previous chapters focused on the first simplicity postulate, which states that simple models are more plausible than complex models a priori–that is, before any data is considered. The present chapter discusses the more popular second simplicity postulate, which addresses how these prior plausibilities are updated when data become available: When the observed data are perfectly consistent both with a simple model and with a more complex model, it is the simple model that receives the most support. This occurs because the complex model hedges its bets and spreads out its predictions across a wider range of data patterns, whereas the predictions from the simple model are relatively precise. The degree of the support for and against a simple model is quantified by the Bayes factor. The methodology is illustrated with two examples.
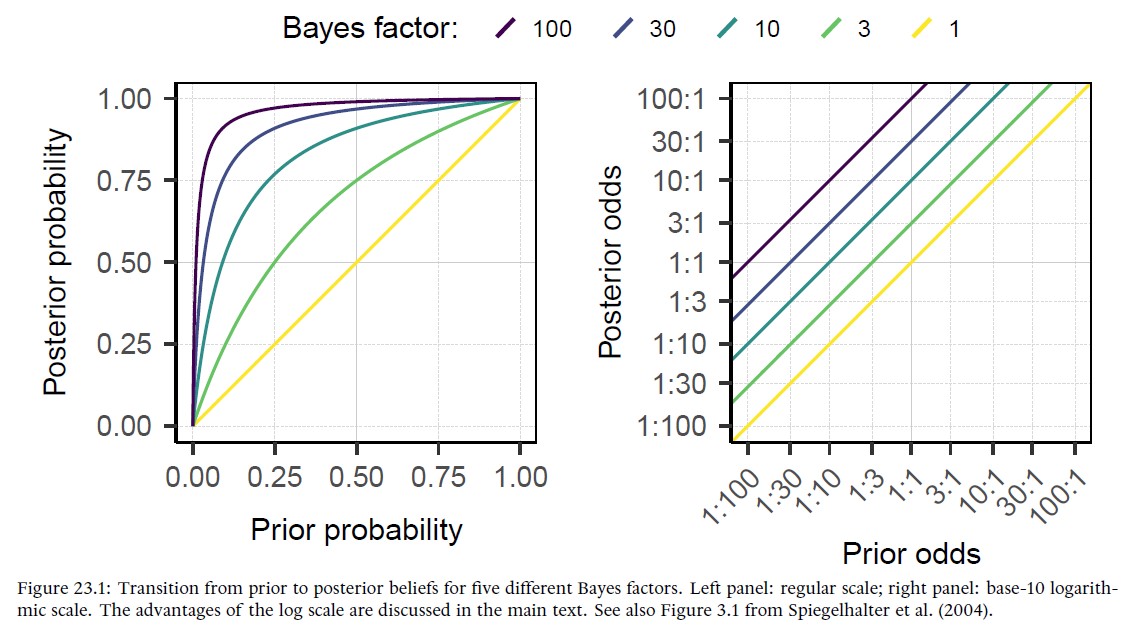
Chapter 23. The Strength of Evidence [with Frederik Aust]
This chapter describes how to communicate and interpret the strength of evidence (sometimes called ‘the weight of evidence’) provided by a Bayes factor.
Chapter 24. Surprise Lost is Confidence Gained [with Quentin F. Gronau]
Bayes’ rule connects evidence (i.e., change in belief brought about by the data) to relative unsurprise (i.e., predictive performance). This little-known aspect of Bayes’ rule allows Bayes factors to be obtained through a convenient short-cut: instead of evaluating the ratio of the marginal likelihood for the null-hypothesis H0 versus the marginal likelihood for the alternative hypothesis H1, one may instead consider the prior and posterior distribution under H1 and assess the change from prior to posterior ordinate evaluated at the value specified under H0. This magical trick is known as the Savage-Dickey density ratio.
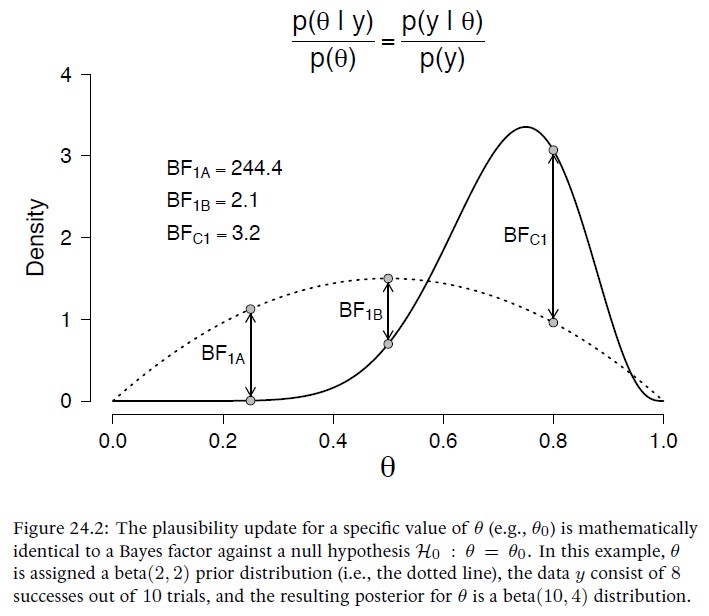
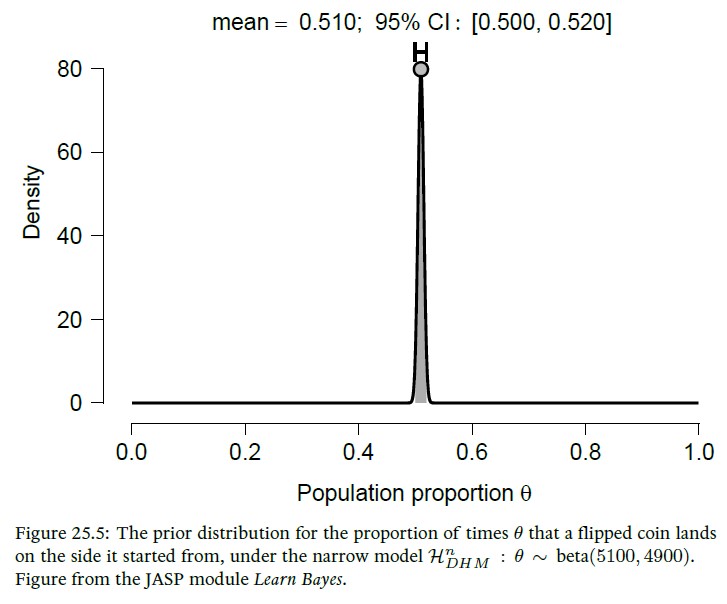
Chapter 25. Diaconis’s Wobbly Coin
This chapter features a series of Bayes factor tests for the hypothesis that a coin, when flipped in the air and caught by hand, tends to come up on the same side that it started (Diaconis et al. 2007). Similar to the analyses presented in Chapter 17, we explore several prior distributions for the ‘same side’ probability θ. Aggressive prior distributions incorporate strong background knowledge and allow for more meaningful conclusions.
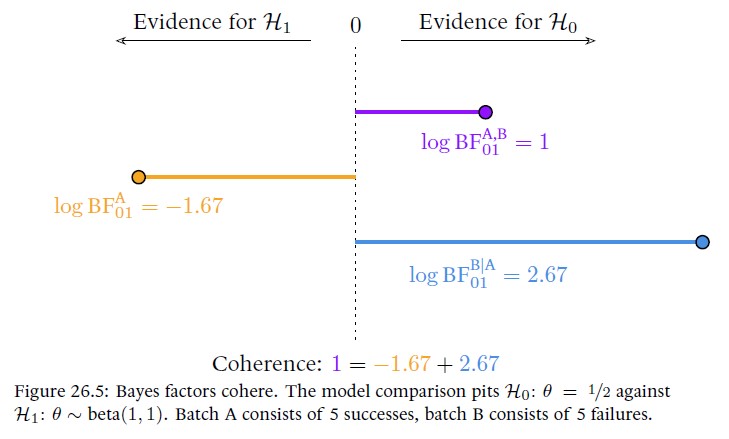
Chapter 26. The Coherence of Evidence Accumulation
The goal of this chapter is twofold. First, we wish to stress that Bayes factors cohere, in the sense of this chapter’s epigraph: the final Bayes factor is exactly the same no matter if the data were analyzed all at once, batch-by-batch, or one observation at a time. Second, the reason why Bayes factors cohere is because they measure relative predictive adequacy, and the quality of the predictions is determined by the prior distribution on the model parameters, which is updated coherently by incoming data. The fact that Bayes factors depend on this prior parameter distribution is often bemoaned, and it is widely regarded as the method’s Achilles heel. This chapter demonstrates that such lamentations are misplaced, and that the dependence on the prior distribution ought instead to be regarded as one of the Bayes factor’s main selling points: if the Bayes factor would not depend on the prior parameter distribution in exactly the way it does, the inference would be incoherent (i.e., internally inconsistent, demonstrably silly, ludicrous, farcical). The conclusion can be put plainly: Bayes factors are right, and everything else is wrong.
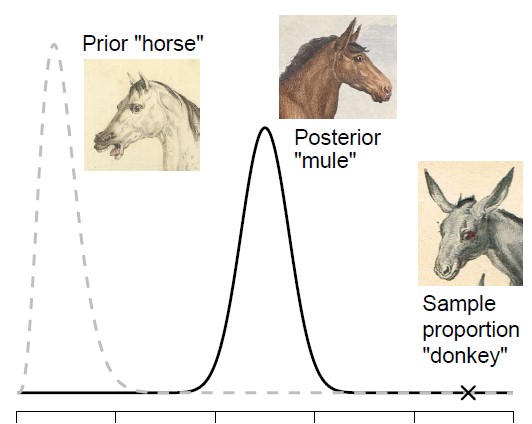
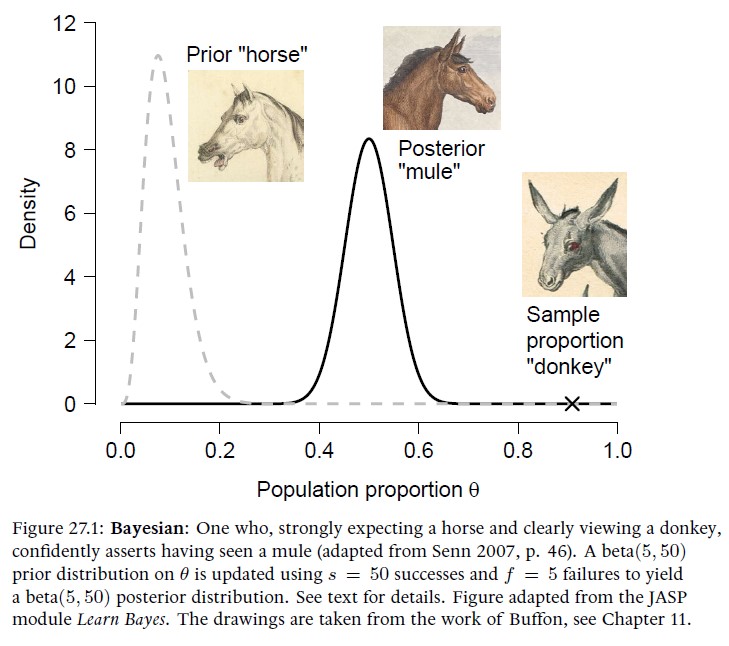
Chapter 27. Senn’s Stubborn Mule [with Frederik Aust and Quentin F. Gronau]
As demonstrated in the previous chapters, one attractive feature of Bayesian inference is the ability to take into account background knowledge by encoding it in the prior distribution. Such informed prior distributions can greatly accelerate the learning process; however, it may occasionally happen that the background knowledge points strongly in the wrong direction. This unfortunate scenario is known as prior-data conflict, and it arises when the Bayesian is both stubborn (i.e., the informed prior distribution is relatively peaked) and wrong (i.e., most of the prior mass is assigned to parameter values that are undercut by the data). The goal of this chapter is to outline how a Bayesian may protect themselves against this eventuality by adopting a mixture prior consisting of an informed prior distribution and a relatively vague ‘insurance’ prior distribution. The insurance prior protects the Bayesian against the worst consequences of an eventual prior-data conflict, but –as is the case with every insurance– it does come with a cost.
In the near future we’ll be adding several other chapters on the topic of Bayes factor hypothesis testing, as well as couple of overview chapters. Stay tuned!

References
van Bork, R., Romeijn, J.-W., & Wagenmakers, E.-J. (2024). Simplicity in Bayesian nested–model comparisons: Popper’s disagreement with Wrinch and Jeffreys revisited. Manuscript submitted for publication. Preprint URL: https://osf.io/preprints/psyarxiv/p57cy.
Wagenmakers, E.-J., & Matzke, D. (2024). Bayesian inference from the ground up: The theory of common sense.